Что такое кодирование и декодирование. Кодирование и декодирование цифровой информации Что такое декодирование в информатике кратко
Для обмена информацией с другими людьми человек использует естественные языки. Наряду с естественными языками были разработаны формальные языки для профессионального применения их в какой-либо сфере. Представление информации с помощью какого-либо языка часто называют кодированием. Код набор символов (условных обозначений) для представления информации. Код система условных знаков (символов) для передачи, обработки и хранения информации(со общения). Кодирование процесс представления информации (сообщения) в виде кода. Все множество символов, используемых для кодирования, называется алфавитом кодирования. Например, в памяти компьютера любая информация кодируется с помощью двоичного алфавита, содержащего всего два символа: 0 и1. Декодирование - процесс обратного преобразования кода к форме исходной символьной системы, т.е. получение исходного сообщения. Например: перевод с азбуки Морзе в письменный текст на русском языке. В более широком смысле декодирование это процесс восстановления содержания закодированного сообщения. При таком подходе процесс записи текста с помощью русского алфавита можно рассматривать в качестве кодирования, а его чтение это декодирование.
Способы кодирования информации. Для кодирования одной и той же информации могут быть использованы разные способы; их выбор зависит от ряда обстоятельств: цели кодирования, условий, имеющихся средств. Если надо записать текст в темпе речи используем стенографию; если надо передать текст за границу используем английский алфавит; если надо представить текст в виде, понятном для грамотного русского человека, записываем его по правилам грамматики русского языка. «Здравствуй, Саша!» «Zdravstvuy, Sasha!»
Выбор способа кодирования информации может быть связан с предполагаемым способом ее обработки. Покажем это на примере представления чисел количественной информации. Используя русский алфавит, можно записать число "тридцать пять". Используя же алфавит арабской десятичной системы счисления, пишем «35». Второй способ не только короче первого, но и удобнее для выполнения вычислений.
Шифрование сообщения . В некоторых случаях возникает потребность засекречивания текста сообщения или документа, для того чтобы его не смогли прочитать те, кому не положено. Это называется защитой от несанкционированного доступа. В таком случае секретный текст шифруется. В давние времена шифрование называлось тайнописью. Шифрование представляет собой процесс превращения открытого текста в зашифрованный, а дешифрование процесс обратного преобразования, при котором восстанавливается исходный текст. Шифрование это тоже кодирование, но с засекреченным методом, известным только источнику и адресату. Методами шифрования занимается наука под названием криптография.
Двоичное кодирование в компьютере . Вся информация, которую обрабатывает компьютер должна быть представлена двоичным кодом с помощью двух цифр: 0 и 1. Эти два символа принято называть двоичными цифрами или битами. С помощью двух цифр 0 и 1 можно закодировать любое сообщение. Это явилось причиной того, что в компьютере обязательно должно быть организованно два важных процесса: кодирование и декодирование. Кодирование – преобразование входной информации в форму, воспринимаемую компьютером, т.е. двоичный код. Декодирование – преобразование данных из двоичного кода в форму, понятную человеку. Привет! 1001011
Информация и ее кодирование
Различные подходы к определению понятия «информация». Виды информационных процессов. Информационный аспект в деятельности человека
Информация (лат. informatio — разъяснение, изложение, набор сведений) — базовое понятие в информатике, которому нельзя дать строгого определения, а можно только пояснить:
- информация — это новые факты, новые знания;
- информация — это сведения об объектах и явлениях окружающей среды, которые повышают уровень осведомленности человека;
- информация — это сведения об объектах и явлениях окружающей среды, которые уменьшают степень неопределенности знаний об этих объектах или явлениях при принятии определенных решений.
Понятие «информация» является общенаучным, т. е. используется в различных науках: физике, биологии, кибернетике, информатике и др. При этом в каждой науке данное понятие связано с различными системами понятий. Так, в физике информация рассматривается как антиэнтропия (мера упорядоченности и сложности системы). В биологии понятие «информация» связывается с целесообразным поведением живых организмов, а также с исследованиями механизмов наследственности. В кибернетике понятие «информация» связано с процессами управления в сложных системах.
Основными социально значимыми свойствами информации являются:
- полезность;
- доступность (понятность);
- актуальность;
- полнота;
- достоверность;
- адекватность.
В человеческом обществе непрерывно протекают информационные процессы: люди воспринимают информацию из окружающего мира с помощью органов чувств, осмысливают ее и принимают определенные решения, которые, воплощаясь в реальные действия, воздействуют на окружающий мир.
Информационный процесс — это процесс сбора (приема), передачи (обмена), хранения, обработки (преобразования) информации.
Сбор информации — это процесс поиска и отбора необходимых сообщений из разных источников (работа со специальной литературой, справочниками; проведение экспериментов; наблюдения; опрос, анкетирование; поиск в информационно-справочных сетях и системах и т. д.).
Передача информации — это процесс перемещения сообщений от источника к приемнику по каналу передачи. Информация передается в форме сигналов — звуковых, световых, ультразвуковых, электрических, текстовых, графических и др. Каналами передачи могут быть воздушное пространство, электрические и оптоволоконные кабели, отдельные люди, нервные клетки человека и т. д.
Хранение информации — это процесс фиксирования сообщений на материальном носителе. Сейчас для хранения информации используются бумага, деревянные, тканевые, металлические и другие поверхности, кино- и фотопленки, магнитные ленты, магнитные и лазерные диски, флэш-карты и др.
Обработка информации — это процесс получения новых сообщений из имеющихся. Обработка информации является одним из основных способов увеличения ее количества. В результате обработки из сообщения одного вида можно получить сообщения других видов.
Защита информации — это процесс создания условий, которые не допускают случайной потери, повреждения, изменения информации или несанкционированного доступа к ней. Способами защиты информации являются создание ее резервных копий, хранение в защищенном помещении, предоставление пользователям соответствующих прав доступа к информации, шифрование сообщений и др.
Язык как способ представления и передачи информации
В зависимости от способа восприятия знаки делятся на:
- зрительные (буквы и цифры, математические знаки, музыкальные ноты, дорожные знаки и др.);
- слуховые (устная речь, звонки, сирены, гудки и др.);
- осязательные (азбука Брайля для слепых, жесты-касания и др.);
- обонятельные;
- вкусовые.
Для долговременного хранения знаки записывают на носители информации.
Для передачи информации используются знаки в виде сигналов (световые сигналы светофора, звуковой сигнал школьного звонка и т. д.).
По способу связи между формой и значением знаки делятся на:
- иконические — их форма похожа на отображаемый объект (например, значок папки «Мой компьютер» на «Рабочем столе» компьютера);
- символы — связь между их формой и значением устанавливается по общепринятому соглашению (например, буквы, математические символы ∫, ≤, ⊆, ∞; символы химических элементов).
Для представления информации используются знаковые системы, которые называются языками . Основу любого языка составляет алфавит — набор символов, из которых формируется сообщение, и набор правил выполнения операций над символами.
Языки делятся на:
- естественные (разговорные) — русский, английский, немецкий и др.;
- формальные — встречающиеся в специальных областях человеческой деятельности (например, язык алгебры, языки программирования, электрических схем и др.)
Системы счисления также можно рассматривать как формальные языки. Так, десятичная система счисления — это язык, алфавит которого состоит из десяти цифр 0..9, двоичная система счисления — язык, алфавит которого состоит из двух цифр — 0 и 1.
Методы измерения количества информации: вероятностный и алфавитный
Единицей измерения количества информации является бит . 1 бит — это количество информации, содержащейся в сообщении, которое вдвое уменьшает неопределенность знаний о чем-либо.
Связь между количеством возможных событий N и количеством информации I определяется формулой Хартли:
Например, пусть шарик находится в одной из четырех коробок. Таким образом, имеется четыре равновероятных события (N = 4). Тогда по формуле Хартли 4 = 2 I . Отсюда I = 2. То есть сообщение о том, в какой именно коробке находится шарик, содержит 2 бита информации.
Алфавитный подход
При алфавитном подходе к определению количества информации отвлекаются от содержания (смысла) информации и рассматривают ее как последовательность знаков определенной знаковой системы. Набор символов языка (алфавит) можно рассматривать как различные возможные события. Тогда, если считать, что появление символов в сообщении равновероятно, по формуле Хартли можно рассчитать, какое количество информации несет каждый символ:
Например, в русском языке 32 буквы (буква ё обычно не используется), т. е. количество событий будет равно 32. Тогда информационный объем одного символа будет равен:
I = log 2 32 = 5 битов.
Если N не является целой степенью 2, то число log 2 N не является целым числом, и для I надо выполнять округление в большую сторону. При решении задач в таком случае I можно найти как log 2 N", где N′ — ближайшая к N степень двойки — такая, что N′ > N.
Например, в английском языке 26 букв. Информационный объем одного символа можно найти так:
N = 26; N" = 32; I = log 2 N" = log 2 (2 5) = 5 битов.
Если количество символов алфавита равно N, а количество символов в записи сообщения равно М, то информационный объем данного сообщения вычисляется по формуле:
I = M · log 2 N.
Примеры решения задач
Пример 1. Световое табло состоит из лампочек, каждая из которых может находиться в одном из двух состояний («включено» или «выключено»). Какое наименьшее количество лампочек должно находиться на табло, чтобы с его помощью можно было передать 50 различных сигналов?
Решение. С помощью n лампочек, каждая из которых может находиться в одном из двух состояний, можно закодировать 2 n сигналов. 2 5 < 50 < 2 6 , поэтому пяти лампочек недостаточно, а шести хватит.
Ответ: 6.
Пример 2. Метеорологическая станция ведет наблюдения за влажностью воздуха. Результатом одного измерения является целое число от 0 до 100, которое записывается при помощи минимально возможного количества битов. Станция сделала 80 измерений. Определите информационный объем результатов наблюдений.
Решение. В данном случае алфавитом является множество целых чисел от 0 до 100. Всего таких значений 101. Поэтому информационный объем результатов одного измерения I = log 2 101. Это значение не будет целочисленным. Заменим число 101 ближайшей к нему степенью двойки, большей 101. Это число 128 = 27. Принимаем для одного измерения I = log 2 128 = 7 битов. Для 80 измерений общий информационный объем равен:
80 · 7 = 560 битов = 70 байтов.
Ответ: 70 байтов.
Вероятностный подход
Вероятностный подход к измерению количества информации применяют, когда возможные события имеют различные вероятности реализации. В этом случае количество информации определяют по формуле Шеннона:
$I=-∑↙{i=1}↖{N}p_ilog_2p_i$,
где $I$ — количество информации;
$N$ — количество возможных событий;
$p_i$ — вероятность $i$-го события.
Например, пусть при бросании несимметричной четырехгранной пирамидки вероятности отдельных событий будут равны:
$p_1={1}/{2}, p_2={1}/{4}, p_3={1}/{8}, p_4={1}/{8}$.
Тогда количество информации, которое будет получено после реализации одного из них, можно вычислить по формуле Шеннона:
$I=-({1}/{2}·log_2{1}/{2}+{1}/{4}·log_2{1}/{4}+{1}/{8}·log_2{1}/{8}+{1}/{8}·log_2{1}/{8})={14}/{8}$ битов $= 1.75 $бита.
Единицы измерения количества информации
Наименьшей единицей информации является бит (англ. binary digit (bit) — двоичная единица информации).
Бит — это количество информации, необходимое для однозначного определения одного из двух равновероятных событий. Например, один бит информации получает человек, когда он узнает, опаздывает с прибытием нужный ему поезд или нет, был ночью мороз или нет, присутствует на лекции студент Иванов или нет и т. д.
В информатике принято рассматривать последовательности длиной 8 битов. Такая последовательность называется байтом.
Производные единицы измерения количества информации:
1 байт = 8 битов
1 килобайт (Кб) = 1024 байта = 2 10 байтов
1 мегабайт (Мб) = 1024 килобайта = 2 20 байтов
1 гигабайт (Гб) = 1024 мегабайта = 2 30 байтов
1 терабайт (Тб) = 1024 гигабайта = 2 40 байтов
Процесс передачи информации. Виды и свойства источников и приемников информации. Сигнал, кодирование и декодирование, причины искажения информации при передаче
Информация передается в виде сообщений от некоторого источника информации к ее приемнику посредством канала связи между ними.
В качестве источника информации может выступать живое существо или техническое устройство. Источник посылает передаваемое сообщение, которое кодируется в передаваемый сигнал.
Сигнал — это материально-энергетическая форма представления информации. Другими словами, сигнал — это переносчик информации, один или несколько параметров которого, изменяясь, отображают сообщение. Сигналы могут быть аналоговыми (непрерывными) или дискретными (импульсными).
Сигнал посылается по каналу связи. В результате в приемнике появляется принимаемый сигнал, который декодируется и становится принимаемым сообщением.
Передача информации по каналам связи часто сопровождается воздействием помех, вызывающих искажение и потерю информации.
Примеры решения задач
Пример 1. Для кодирования букв А, З, Р, О используются двухразрядные двоичные числа 00, 01, 10, 11 соответственно. Этим способом закодировали слово РОЗА и результат записали шестнадцатеричным кодом. Указать полученное число.
Решение. Запишем последовательность кодов для каждого символа слова РОЗА: 10 11 01 00. Если рассматривать полученную последовательность как двоичное число, то в шестнадцатеричном коде оно будет равно: 1011 0100 2 = В4 16 .
Ответ: В4 16 .
Скорость передачи информации и пропускная способность канала связи
Прием/передача информации может происходить с разной скоростью. Количество информации, передаваемое за единицу времени, есть скорость передачи информации , или скорость информационного потока.
Скорость выражается в битах в секунду (бит/с) и кратных им Кбит/с и Мбит/с, а также в байтах в секунду (байт/с) и кратных им Кбайт/с и Мбайт/с.
Максимальная скорость передачи информации по каналу связи называется пропускной способностью канала.
Примеры решения задач
Пример 1. Скорость передачи данных через ADSL-соединение равна 256000 бит/с. Передача файла через данное соединение заняла 3 мин. Определите размер файла в килобайтах.
Решение. Размер файла можно вычислить, если умножить скорость передачи информации на время передачи. Выразим время в секундах: 3 мин = 3 ⋅ 60 = 180 с. Выразим скорость в килобайтах в секунду: 256000 бит/с = 256000: 8: 1024 Кбайт/с. При вычислении размера файла для упрощения расчетов выделим степени двойки:
Размер файла = (256000: 8: 1024) ⋅ (3 ⋅ 60) = (2 8 ⋅ 10 3: 2 3: 2 10) ⋅ (3 ⋅ 15 ⋅ 2 2) = (2 8 ⋅ 125 ⋅ 2 3: 2 3: 2 10) ⋅ (3 ⋅ 15 ⋅ 2 2) = 125 ⋅ 45 = 5625 Кбайт.
Ответ: 5625 Кбайт.
Представление числовой информации. Сложение и умножение в разных системах счисления
Представление числовой информации с помощью систем счисления
Для представления информации в компьютере используется двоичный код, алфавит которого состоит из двух цифр — 0 и 1. Каждая цифра машинного двоичного кода несет количество информации, равное одному биту.
Система счисления — это система записи чисел с помощью определенного набора цифр.
Система счисления называется позиционной , если одна и та же цифра имеет различное значение, которое определяется ее местом в числе.
Позиционной является десятичная система счисления. Например, в числе 999 цифра «9» в зависимости от позиции означает 9, 90, 900.
Римская система счисления является непозиционной . Например, значение цифры Х в числе ХХІ остается неизменным при вариации ее положения в числе.
Позиция цифры в числе называется разрядом . Разряд числа возрастает справа налево, от младших разрядов к старшим.
Количество различных цифр, употребляемых в позиционной системе счисления, называется ее основанием .
Развернутая форма числа — это запись, которая представляет собой сумму произведений цифр числа на значение позиций.
Например: 8527 = 8 ⋅ 10 3 + 5 ⋅ 10 2 + 2 ⋅ 10 1 + 7 ⋅ 10 0 .
Развернутая форма записи чисел произвольной системы счисления имеет вид
$∑↙{i=n-1}↖{-m}a_iq^i$,
где $X$ — число;
$a$ — цифры численной записи, соответствующие разрядам;
$i$ — индекс;
$m$ — количество разрядов числа дробной части;
$n$ — количество разрядов числа целой части;
$q$ — основание системы счисления.
Например, запишем развернутую форму десятичного числа $327.46$:
$n=3, m=2, q=10.$
$X=∑↙{i=2}↖{-2}a_iq^i=a_2·10^2+a_1·10^1+a_0·10^0+a_{-1}·10^{-1}+a_{-2}·10^{-2}=3·10^2+2·10^1+7·10^0+4·10^{-1}+6·10^{-2}$
Если основание используемой системы счисления больше десяти, то для цифр вводят условное обозначение со скобкой вверху или буквенное обозначение: В — двоичная система, О — восмеричная, Н — шестнадцатиричная.
Например, если в двенадцатеричной системе счисления 10 = А, а 11 = В, то число 7А,5В 12 можно расписать так:
7А,5В 12 = В ⋅ 12 -2 + 5 ⋅ 2 -1 + А ⋅ 12 0 + 7 ⋅ 12 1 .
В шестнадцатеричной системе счисления 16 цифр, обозначаемых 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F, что соответствует следующим числам десятеричной системы счисления: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15. Примеры чисел: 17D,ECH; F12AH.
Перевод чисел в позиционных системах счисления
Перевод чисел из произвольной системы счисления в десятичную
Для перевода числа из любой позиционной системы счисления в десятичную необходимо использовать развернутую форму числа, заменяя, если это необходимо, буквенные обозначения соответствующими цифрами. Например:
1101 2 = 1 ⋅ 2 3 + 1 ⋅ 2 2 + 0 ⋅ 2 1 + 1 ⋅ 2 0 = 13 10 ;
17D,ECH = 12 ⋅ 16 -2 + 14 ⋅ 16 -1 + 13 ⋅ 160 + 7 ⋅ 16 1 + 1 ⋅ 16 2 = 381,921875.
Перевод чисел из десятичной системы счисления в заданную
Для преобразования целого числа десятичной системы счисления в число любой другой системы счисления последовательно выполняют деление нацело на основание системы счисления, пока не получат нуль. Числа, которые возникают как остаток от деления на основание системы, представляют собой последовательную запись разрядов числа в выбранной системе счисления от младшего разряда к старшему. Поэтому для записи самого числа остатки от деления записывают в обратном порядке.
Например, переведем десятичное число 475 в двоичную систему счисления. Для этого будем последовательно выполнять деление нацело на основание новой системы счисления, т. е. на 2:
Читая остатки от деления снизу вверх, получим 111011011.
Проверка:
1 ⋅ 2 8 + 1 ⋅ 2 7 + 1 ⋅ 2 6 + 0 ⋅ 2 5 + 1 ⋅ 2 4 + 1 ⋅ 2 3 + 0 ⋅ 2 2 + 1 ⋅ 2 1 + 1 ⋅ 2 0 = 1 + 2 + 8 + 16 + 64 + 128 + 256 = 475 10 .
Для преобразования десятичных дробей в число любой системы счисления последовательно выполняют умножение на основание системы счисления, пока дробная часть произведения не будет равна нулю. Полученные целые части являются разрядами числа в новой системе, и их необходимо представлять цифрами этой новой системы счисления. Целые части в дальнейшем отбрасываются.
Например, переведем десятичную дробь 0,375 10 в двоичную систему счисления:

Полученный результат — 0,011 2 .
Не каждое число может быть точно выражено в новой системе счисления, поэтому иногда вычисляют только требуемое количество разрядов дробной части.
Перевод чисел из двоичной системы счисления в восьмеричную и шестнадцатеричную и обратно
Для записи восьмеричных чисел используются восемь цифр, т. е. в каждом разряде числа возможны 8 вариантов записи. Каждый разряд восьмеричного числа содержит 3 бита информации (8 = 2 І ; І = 3).
Таким образом, чтобы из восьмеричной системы счисления перевести число в двоичный код, необходимо каждую цифру этого числа представить триадой двоичных символов. Лишние нули в старших разрядах отбрасываются.
Например:
1234,777 8 = 001 010 011 100,111 111 111 2 = 1 010 011 100,111 111 111 2 ;
1234567 8 = 001 010 011 100 101 110 111 2 = 1 010 011 100 101 110 111 2 .
При переводе двоичного числа в восьмеричную систему счисления нужно каждую триаду двоичных цифр заменить восьмеричной цифрой. При этом, если необходимо, число выравнивается путем дописывания нулей перед целой частью или после дробной.
Например:
1100111 2 = 001 100 111 2 = 147 8 ;
11,1001 2 = 011,100 100 2 = 3,44 8 ;
110,0111 2 = 110,011 100 2 = 6,34 8 .
Для записи шестнадцатеричных чисел используются шестнадцать цифр, т. е. для каждого разряда числа возможны 16 вариантов записи. Каждый разряд шестнадцатеричного числа содержит 4 бита информации (16 = 2 І ; І = 4).
Таким образом, для перевода двоичного числа в шестнадцатеричное его нужно разбить на группы по четыре цифры и преобразовать каждую группу в шестнадцатеричную цифру.
Например:
1100111 2 = 0110 0111 2 = 67 16 ;
11,1001 2 = 0011,1001 2 = 3,9 16 ;
110,0111001 2 = 0110,0111 0010 2 = 65,72 16 .
Для перевода шестнадцатеричного числа в двоичный код необходимо каждую цифру этого числа представить четверкой двоичных цифр.
Например:
1234,AB77 16 = 0001 0010 0011 0100,1010 1011 0111 0111 2 = 1 0010 0011 0100,1010 1011 0111 0111 2 ;
CE4567 16 = 1100 1110 0100 0101 0110 0111 2 .
При переводе числа из одной произвольной системы счисления в другую нужно выполнить промежуточное преобразование в десятичное число. При переходе из восьмеричного счисления в шестнадцатеричное и обратно используется вспомогательный двоичный код числа.
Например, переведем троичное число 211 3 в семеричную систему счисления. Для этого сначала преобразуем число 211 3 в десятичное, записав его развернутую форму:
211 3 = 2 ⋅ 3 2 + 1 ⋅ 3 1 + 1 ⋅ 3 0 = 18 + 3 + 1 = 22 10 .
Затем переведем десятичное число 22 10 в семеричную систему счисления делением нацело на основание новой системы счисления, т. е. на 7:
Итак, 211 3 = 31 7 .
Примеры решения задач
Пример 1. В системе счисления с некоторым основанием число 12 записывается в виде 110. Указать это основание.
Решение. Обозначим искомое основание п. По правилу записи чисел в позиционных системах счисления 12 10 = 110 n = 0 ·n 0 + 1 · n 1 + 1 · n 2 . Составим уравнение: n 2 + n = 12 . Найдем натуральный корень уравнения (отрицательный корень не подходит, т. к. основание системы счисления, по определению, натуральное число большее единицы): n = 3 . Проверим полученный ответ: 110 3 = 0· 3 0 + 1 · 3 1 + 1 · 3 2 = 0 + 3 + 9 = 12 .
Ответ: 3.
Пример 2. Указать через запятую в порядке возрастания все основания систем счисления, в которых запись числа 22 оканчивается на 4.
Решение. Последняя цифра в записи числа представляет собой остаток от деления числа на основание системы счисления. 22 - 4 = 18. Найдем делители числа 18. Это числа 2, 3, 6, 9, 18. Числа 2 и 3 не подходят, т. к. в системах счисления с основаниями 2 и 3 нет цифры 4. Значит, искомыми основаниями являются числа 6, 9 и 18. Проверим полученный результат, записав число 22 в указанных системах счисления: 22 10 = 34 6 = 24 9 = 14 18 .
Ответ: 6, 9, 18.
Пример 3. Указать через запятую в порядке возрастания все числа, не превосходящие 25, запись которых в двоичной системе счисления оканчивается на 101. Ответ записать в десятичной системе счисления.
Решение. Для удобства воспользуемся восьмеричной системой счисления. 101 2 = 5 8 . Тогда число х можно представить как x = 5 · 8 0 + a 1 · 8 1 + a 2 · 8 2 + a 3 · 8 3 + ... , где a 1 , a 2 , a 3 , … — цифры восьмеричной системы. Искомые числа не должны превосходить 25, поэтому разложение нужно ограничить двумя первыми слагаемыми (8 2 > 25), т. е. такие числа должны иметь представление x = 5 + a 1 · 8. Поскольку x ≤ 25 , допустимыми значениями a 1 будут 0, 1, 2. Подставив эти значения в выражение для х, получим искомые числа:
a 1 = 0; x = 5 + 0 · 8 = 5;.
a 1 =1; x = 5 + 1 · 8 = 13;.
a 1 = 2; x = 5 + 2 · 8 = 21;.
Выполним проверку:
13 10 = 1101 2 ;
21 10 = 10101 2 .
Ответ: 5, 13, 21.
Арифметические операции в позиционных системах счисления
Правила выполнения арифметических действий над двоичными числами задаются таблицами сложения, вычитания и умножения.
Правило выполнения операции сложения одинаково для всех систем счисления: если сумма складываемых цифр больше или равна основанию системы счисления, то единица переносится в следующий слева разряд. При вычитании, если необходимо, делают заем.
Пример выполнения сложения : сложим двоичные числа 111 и 101, 10101 и 1111:

Пример выполнения вычитания: вычтем двоичные числа 10001 - 101 и 11011 - 1101:

Пример выполнения умножения: умножим двоичные числа 110 и 11, 111 и 101:

Аналогично выполняются арифметические действия в восьмеричной, шестнадцатеричной и других системах счисления. При этом необходимо учитывать, что величина переноса в следующий разряд при сложении и заем из старшего разряда при вычитании определяется величиной основания системы счисления.
Например, выполним сложение восьмеричных чисел 36 8 и 15 8 , а также вычитание шестнадцатеричных чисел 9С 16 и 67 16:

При выполнении арифметических операций над числами, представленными в разных системах счисления, нужно предварительно перевести их в одну и ту же систему.
Представление чисел в компьютере
Формат с фиксированной запятой
В памяти компьютера целые числа хранятся в формате с фиксированной запятой : каждому разряду ячейки памяти соответствует один и тот же разряд числа, «запятая» находится вне разрядной сетки.
Для хранения целых неотрицательных чисел отводится 8 битов памяти. Минимальное число соответствует восьми нулям, хранящимся в восьми битах ячейки памяти, и равно 0. Максимальное число соответствует восьми единицам и равно
1 ⋅ 2 7 + 1 ⋅ 2 6 + 1 ⋅ 2 5 + 1 ⋅ 2 4 + 1 ⋅ 2 3 + 1 ⋅ 2 2 + 1 ⋅ 2 1 + 1 ⋅ 2 0 = 255 10 .
Таким образом, диапазон изменения целых неотрицательных чисел — от 0 до 255.
Для п-разрядного представления диапазон будет составлять от 0 до 2 n - 1.
Для хранения целых чисел со знаком отводится 2 байта памяти (16 битов). Старший разряд отводится под знак числа: если число положительное, то в знаковый разряд записывается 0, если число отрицательное — 1. Такое представление чисел в компьютере называется прямым кодом .
Для представления отрицательных чисел используется дополнительный код . Он позволяет заменить арифметическую операцию вычитания операцией сложения, что существенно упрощает работу процессора и увеличивает его быстродействие. Дополнительный код отрицательного числа А, хранящегося в п ячейках, равен 2 n − |А|.
Алгоритм получения дополнительного кода отрицательного числа:
1. Записать прямой код числа в п двоичных разрядах.
2. Получить обратный код числа . (Обратный код образуется из прямого кода заменой нулей единицами, а единиц — нулями, кроме цифр знакового разряда. Для положительных чисел обратный код совпадает с прямым. Используется как промежуточное звено для получения дополнительного кода.)
3. Прибавить единицу к полученному обратному коду.
Например, получим дополнительный код числа -2014 10 для шестнадцатиразрядного представления:
При алгебраическом сложении двоичных чисел с использованием дополнительного кода положительные слагаемые представляют в прямом коде, а отрицательные — в дополнительном коде. Затем суммируют эти коды, включая знаковые разряды, которые при этом рассматриваются как старшие разряды. При переносе из знакового разряда единицу переноса отбрасывают. В результате получают алгебраическую сумму в прямом коде, если эта сумма положительная, и в дополнительном — если сумма отрицательная.
Например:
1) Найдем разность 13 10 - 12 10 для восьмибитного представления. Представим заданные числа в двоичной системе счисления:
13 10 = 1101 2 и 12 10 = 1100 2 .
Запишем прямой, обратный и дополнительный коды для числа -12 10 и прямой код для числа 13 10 в восьми битах:
Вычитание заменим сложением (для удобства контроля за знаковым разрядом условно отделим его знаком «_»):

Так как произошел перенос из знакового разряда, первую единицу отбрасываем, и в результате получаем 00000001.
2) Найдем разность 8 10 - 13 10 для восьмибитного представления.
Запишем прямой, обратный и дополнительный коды для числа -13 10 и прямой код для числа 8 10 в восьми битах:
Вычитание заменим сложением:
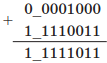
В знаковом разряде стоит единица, а значит, результат получен в дополнительном коде. Перейдем от дополнительного кода к обратному, вычтя единицу:
11111011 - 00000001 = 11111010.
Перейдем от обратного кода к прямому, инвертируя все цифры, за исключением знакового (старшего) разряда: 10000101. Это десятичное число -5 10 .
Так как при п-разрядном представлении отрицательного числа А в дополнительном коде старший разряд выделяется для хранения знака числа, минимальное отрицательное число равно: А = -2 n-1 , а максимальное: |А| = 2 n-1 или А = -2 n-1 - 1.
Определим диапазон чисел, которые могут храниться в оперативной памяти в формате длинных целых чисел со знаком (для хранения таких чисел отводится 32 бита памяти). Минимальное отрицательное число равно
А = -2 31 = -2147483648 10 .
Максимальное положительное число равно
А = 2 31 - 1 = 2147483647 10 .
Достоинствами формата с фиксированной запятой являются простота и наглядность представления чисел, простота алгоритмов реализации арифметических операций. Недостатком является небольшой диапазон представимых чисел, недостаточный для решения большинства прикладных задач.
Формат с плавающей запятой
Вещественные числа хранятся и обрабатываются в компьютере в формате с плавающей запятой , использующем экспоненциальную форму записи чисел.
Число в экспоненциальном формате представляется в таком виде:
где $m$ — мантисса числа (правильная отличная от нуля дробь);
$q$ — основание системы счисления;
$n$ — порядок числа.
Например, десятичное число 2674,381 в экспоненциальной форме запишется так:
2674,381 = 0,2674381 ⋅ 10 4 .
Число в формате с плавающей запятой может занимать в памяти 4 байта (обычная точность ) или 8 байтов (двойная точность ). При записи числа выделяются разряды для хранения знака мантиссы, знака порядка, порядка и мантиссы. Две последние величины определяют диапазон изменения чисел и их точность.
Определим диапазон (порядок) и точность (мантиссу) для формата чисел обычной точности, т. е. четырехбайтных. Из 32 битов 8 выделяется для хранения порядка и его знака и 24 — для хранения мантиссы и ее знака.
Найдем максимальное значение порядка числа. Из 8 разрядов старший разряд используется для хранения знака порядка, остальные 7 — для записи величины порядка. Значит, максимальное значение равно 1111111 2 = 127 10 . Так как числа представляются в двоичной системе счисления, то
$q^n = 2^{127}≈ 1.7 · 10^{38}$.
Аналогично, максимальное значение мантиссы равно
$m = 2^{23} - 1 ≈ 2^{23} = 2^{(10 · 2.3)} ≈ 1000^{2.3} = 10^{(3 · 2.3)} ≈ 10^7$.
Таким образом, диапазон чисел обычной точности составляет $±1.7 · 10^{38}$.
Кодирование текстовой информации. Кодировка ASCII. Основные используемые кодировки кириллицы
Соответствие между набором символов и набором числовых значений называется кодировкой символа. При вводе в компьютер текстовой информации происходит ее двоичное кодирование. Код символа хранится в оперативной памяти компьютера. В процессе вывода символа на экран производится обратная операция — декодирование , т. е. преобразование кода символа в его изображение.
Присвоенный каждому символу конкретный числовой код фиксируется в кодовых таблицах. Одному и тому же символу в разных кодовых таблицах могут соответствовать разные числовые коды. Необходимые перекодировки текста обычно выполняют специальные программы-конверторы, встроенные в большинство приложений.
Как правило, для хранения кода символа используется один байт (восемь битов), поэтому коды символов могут принимать значение от 0 до 255. Такие кодировки называют однобайтными . Они позволяют использовать 256 символов (N = 2 I = 2 8 = 256). Таблица однобайтных кодов символов называется ASCII (American Standard Code for Information Interchange — Американский стандартный код для обмена информацией). Первая часть таблицы ASCII-кодов (от 0 до 127) одинакова для всех IBM-PC совместимых компьютеров и содержит:
- коды управляющих символов;
- коды цифр, арифметических операций, знаков препинания;
- некоторые специальные символы;
- коды больших и маленьких латинских букв.
Вторая часть таблицы (коды от 128 до 255) бывает различной в различных компьютерах. Она содержит коды букв национального алфавита, коды некоторых математических символов, коды символов псевдографики. Для русских букв в настоящее время используется пять различных кодовых таблиц: КОИ-8, СР1251, СР866, Мас, ISO.
В последнее время широкое распространение получил новый международный стандарт Unicode . В нем отводится по два байта (16 битов) для кодирования каждого символа, поэтому с его помощью можно закодировать 65536 различных символов (N = 2 16 = 65536). Коды символов могут принимать значение от 0 до 65535.
Примеры решения задач
Пример. С помощью кодировки Unicode закодирована следующая фраза:
Я хочу поступить в университет!
Оценить информационный объем этой фразы.
Решение. В данной фразе содержится 31 символ (включая пробелы и знак препинания). Поскольку в кодировке Unicode каждому символу отводится 2 байта памяти, для всей фразы понадобится 31 ⋅ 2 = 62 байта или 31 ⋅ 2 ⋅ 8 = 496 битов.
Ответ: 32 байта или 496 битов.
Кодирование информации
Для осуществления полноценного процесса передачи информации, при котором сам процесс должен успешно завершиться, а сообщение дойти от отправителя до получателя в полном объеме, который, в свою очередь, его правильно трактует, информацию необходимо закодировать.
Определение 1
Кодирование - это преобразование информации из одной ее формы представления в другую, наиболее удобную для её хранения, передачи или обработки.
Способы кодирования информации бывают различные и зависят они, в первую очередь, от целей кодирования.
Наиболее распространенными из которых являются:
- экономность (достигается сокращением записи);
- надежность (информацию необходимо засекретить таким образом, чтобы она была недоступна третьим лицам);
- удобство обработки или восприятия.
Чаще всего кодированию подвергаются тексты на естественных языках (русском, английском и пр.).
Цели кодирования заключаются в доведении идеи отправителя до получателя, обеспечении такой интерпретации полученной информации получателем, которая соответствует замыслу отправителя. Для этого используются специальные системы кодов, состоящие из символов и знаков. Код представляет собой систему условных знаков (символов), предназначенных для представления информации по определенным правилам. В настоящее время понятие «код» трактуется по-разному.
Замечание 1
Некоторые авторы (Р. Бландел, А. Б. Зверинцев, В. Г. Корольке и др.) понимают коды как любую форму представления информации или же как набор однозначных правил, используя которые сообщение можно представить в той или иной форме. Согласно этому определению человеческая речь может выступать в качестве одного из кодов. Это может означать, что в результате кодирования сообщение преобразуется в последовательность, состоящую из произносимых слов.
Другим вариантом трактовки термина «код», сформированного в технической среде под влиянием «математической теории связи (коммуникации)» и использования технических средств коммуникации, является условное преобразование, как правило, взаимно однозначное и обратимое, используя которое сообщения преобразовываются из одной системы знаков в другую. К примерам такого преобразования относят азбуку Морзе, семафорный код и жесты глухонемых. Для данного определения характерно четкое различие языка, который развивался вместе с человеком на протяжении всего этапа эволюции, и кодов, разработанных людьми для определенных целей и подчиняющихся четко сформулированным правилам.
В теории коммуникации кодирование представляют как соответствующую переработку исходной идеи сообщения с целью ее доведения до адресата. При этом в разных конкретных случаях формы передачи информации могут быть различными, например: брошюры, листовки, рекламные ролики па заданную тему и т.д.
Декодирование информации
Определение 2
Декодирование - процесс восстановления изначальной формы представления информации, т. е. обратный процесс кодирования, при котором закодированное сообщение переводится на язык, понятный получателю. В более широком плане это:
а) процесс придания определенного смысла полученным сигналам;
б) процесс выявления первоначального замысла, исходной идеи отправителя, понимания смысла его сообщения.
Если получатель правильно воспримет смысл сообщения, то его реакция будет именно такой, какую и ожидал от него отправитель сообщения. То, каким образом получатель будет расшифровывать сообщение, зависит, как правило, от его индивидуальных особенностей восприятия информации. Так как каждый человек в той или иной степени предвзято и субъективно оценивает события, то, соответственно разные люди воспринимают и понимают одни и те же события по-разному. И это непременно необходимо учитывать при трансляции информации и при коммуникации между людьми.
Модель кодирования/декодирования С. Холла
Особенности системы кодирования-декодирования, которая включает в себя обработку информационного сообщения с целью его передачи и осмысления потребителем, лучше всего рассмотреть на примере коммуникационной модели С. Холла . В основу его теории положены базовые принципы семиотики структурализма, которые предполагают, что любое смысловое сообщение можно сконструировать из знаков, имеющих как явные, так и подразумеваемые смыслы в зависимости от выбора, осуществляемого кодировщиком, т.е. коммуникатором. Согласно основному положению семиотики многообразие смыслов зависит от природы языка, являющегося инструментарием информационной системы, и от смысловых значений, которые заключены в комбинациях знаков и символов в рамках определенной социальной культуры, к которой принадлежат отправитель (кодировщик) и получатель (декодировщик).
Замечание 2
Семиотика подчеркивает семантическую силу закодированного текста, рассматривает смысл информационного сообщения прочно внедренного в текст. С. Холл принимал базовые положения этого подхода, но, в свою очередь, внес в него ряд дополнений.
Согласно Холлу коммуникаторы часто кодируют сообщения, придерживаясь идеологических и пропагандистских целей, а для этого манипулируют языком и медиасредствами (сообщения приобретают «предпочтительный» смысл).
Получатели согласно Холлу не всегда обязаны принимать и декодировать сообщения в том виде, в котором они отправлены. Получатели оказывать сопротивление идеологическому влиянию, применяя при этом альтернативные оценки в соответствии со своим мировоззрением, опытом и взглядами на окружающую систему бытия.
Свою теорию С. Холл сформулировал, используя в качестве примера работу телевидения, но ее можно применить к любым видам средств массовой информации. Суть теории заключается в том, что медиасообщение, проходя на своем пути от источника до получателя, претерпевает ряд преобразований. В результате средства медиакоммуникации передают сообщения, конформные или оппозиционные по отношению к правящим властям, различным общественным, политическим и экономическим социальным институтам. Эти сообщения кодируются зачастую в форме устоявшихся содержательных жанров (к ним можно отнести новости политического, спортивного, экономического содержания; музыкальные передачи, сериалы и пр., в общем все то, что смотрят обыватели), имеющих очевидный содержательный смысл, актуализированную направленность и встроенные руководства для их интерпретации заинтересованной целевой аудиторией. Зрители же, в свою очередь, подходят к содержанию, предлагаемому СМИ, с другими «смысловыми структурами», которые строятся на их собственном здравом смысле, идеях и опыте.
Различные группы людей (или так называемые субкультуры ) занимают разные социальные и культурные ниши этнопространства и по-разному воспринимают сообщения СМИ. В результате своих исследований С. Холл пришел к выводу, что декодированный смысл сообщения не обязательно должен совпадать с первоначальным смыслом, который был закодирован, хотя он и был опосредован уже сложившимися медиажанрами и общей языковой системой. Важным является и то, что декодирование может принимать направления, отличные от предполагаемого, т.е. получатели, образно говоря, могут читать между строк и даже сознательно искажать изначально заложенный смысл сообщения.
Теория Холла содержит ряд принципиальных положений , это:
- многообразие смыслов, заложенных в тексте;
- первичность получателя в определении смысла;
- наличие различных «интерпретативных» сообществ.
Таким образом, мы пришли к определению того, кто такой получатель.
Определение 3
Получатель - это лицо, для которого предназначена передаваемая информация, и которое может интерпретировать ее. Получателю, чтобы понять смысл передаваемого сообщения, нужно его раскодировать (декодировать). В качестве получателя могут выступать как один человек, так и группа лиц, общество в целом или любая его часть. Когда в качестве получателя выступает более одного человека, то это называют аудиторией коммуникации.
Получатель информационного сообщения должен обладать определенными характеристиками, которые представляю собой важные факторы, влияющие на эффективность коммуникации. Главным условием при этом становится способность получателя воспринимать и декодировать отправленное ему сообщение. Эта способность зависит от профессиональной компетентности получателя, его жизненного опыта, принадлежности к той или иной группе, ценностных ориентаций, общей культуры, образовательного и интеллектуального уровня, а также обусловлена социокультурными рамками коммуникативного процесса. Реакция получателя представляет собой основной индикатор эффективности коммуникации.
Мы подробно с вами разобрали непосредственно саму теорию кодирования и декодирования информационных сообщений, в частности модель Холла, которая в большей степени ориентируется на социум.
Однако эти два процесса широко используются во всех сферах жизнедеятельности человека: медицине, технике, образовании и т.д. И каждый из нас ежедневно с ними сталкивается независимо от того, что происходит в окружающей нас жизни.
Кодирование и декодирование информации
За правильное выполненное задание получишь 1 балл . На решение отводится примерно 2 минуты .
Для выполнения задания 5 по информатике необходимо знать:
Кодирование - это перевод информации из одной формы представления в другую.
Декодирование - это обратный процесс кодированию.
Кодирование бывает равномерное и неравномерное ;
- при равномерном кодировании все символы кодируются кодами равной длины; Например : ASCII или Unicode.
- при неравномерном кодировании разные символы могут кодироваться кодами разной длины, это затрудняет декодирование, связанные с появлением неоднозначности кода. Например : Символ А кодируется цифрой 0, Б - последовательностью 01, а В - последовательностью 1. Итак, например, сообщение "011" может быть раскодировано, как AВВ или БВ. При неоднозначность кода информацию можно декодировать по разному.
Для однозначного декодирования код должен удовлетворять условию Фано : никакое кодовое слово не может быть началом другого кодового слова.
4. Кодирование и декодирование цифровой информации
Кодирование информации – это процесс формирования определенного представления информации. Информация совершает переход от исходной формы представления информации в форму, удобную для хранения, передачи или обработки. Декодирование - когда информация совершает обратный переход к исходному представлению информации.
В более узком смысле под термином «кодирование» часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки. Компьютер может обрабатывать только информацию, представленную в числовой форме. Вся другая информация (звуки, изображения, показания приборов и т. д.) для обработки на компьютере должна быть преобразована в числовую форму.
Как правило, вся информация в компьютере представляются с помощью нулей и единиц. Иными словами, компьютеры обычно работают в двоичной системе счисления, поскольку при этом устройства для их обработки получаются значительно более простыми. С помощью двух цифр 0 и 1 можно закодировать любое сообщение.
Инженеров такой способ кодирования привлек простотой технической реализации – есть сигнал или нет сигнала. Эти состояния легко различать. Недостаток двоичного кодирования – длинные коды. Но в технике легче иметь дело с большим числом однотипных элементов, чем с небольшим числом сложных.
Устройства, обеспечивающие кодирование и декодирование, будем называть соответственно кодировщиком и декодировщиком. На рис. 1 приведена схема, иллюстрирующая процесс передачи сообщения в случае перекодировки, а также воздействия помех.
Рис. 1. Процесс передачи сообщения от источника к приемнику
В настоящее время существуют разные способы кодирования и декодирования информации в компьютере. Выбор способа зависит от вида информации, которую необходимо кодировать: текст, число, графическое изображение или звук. Для чисел, кроме того, важную роль играет то, как будет использоваться число: в тексте или в вычислениях, или в процессе ввода-вывода.
Рассмотрим основные принципы кодирования информации в компьютере.
5. Кодирование текстовой информации
Начиная с 60-х годов, компьютеры все больше стали использовать для обработки текстовой информации и в настоящее время большая часть ПК в мире занято обработкой именно текстовой информации.
Для кодирования одного символа требуется один байт информации. Учитывая, что каждый бит принимает значение 1 или 0, получаем, что с помощью 1 байта можно закодировать 256 различных символов. (2 8 =256) Кодирование заключается в том, что каждому символу ставиться в соответствие уникальный двоичный код от 00000000 до 11111111 (или десятичный код от 0 до 255). Важно, что присвоение символу конкретного кода – это вопрос соглашения, которое фиксируется кодовой таблицей.
Например, вы нажимаете на компьютере латинскую букву S. В этом случае в память компьютера записывается код 01010011. Для вывода буквы S на экран в компьютере происходит декодирование – по этому двоичному коду строится его изображение.
Обратите внимание!
Цифры кодируются по стандарту ASCII в двух случаях – при вводе-выводе и когда они встречаются в тексте. Если цифры участвуют в вычислениях, то осуществляется их преобразование в другой двоичный код.
Возьмем число 57. При использовании в тексте каждая цифра будет представлена своим кодом в соответствии с таблицей ASCII. В двоичной системе это – 00110101 00110111. При использовании в вычислениях код этого числа будет получен по правилам перевода в двоичную систему и получим – 00111001.
6. Кодирование графической информации
Под графической информацией можно понимать рисунок, чертеж, фотографию, картинку в книге, изображения на экране телевизора или в кинозале и т. д. Для обсуждения общих принципов кодирования графической информации в качестве конкретного, достаточно общего случая графического объекта выберем изображение на экране телевизора. Это изображение состоит из некоторого количества горизонтальных линий – строк. А каждая строка в свою очередь состоит из элементарных мельчайших единиц изображения – точек, которые принято называть пикселами (picsel – PICture"S ELement – элемент картинки). Пиксел на цветном дисплее может иметь различную окраску, поэтому одного бита на пиксел недостаточно. Для кодирования 4-цветного изображения требуются два бита на пиксел, поскольку два бита могут принимать 4 различных состояния. Может использоваться, например, такой вариант кодировки цветов: 00 - черный, 10 - зеленый, 01 - красный, 11 - коричневый. На RGB-мониторах все разнообразие цветов получается сочетанием базовых цветов - красного (Red), зеленого (Green), синего (Blue), из которых можно получить 8 основных комбинаций:
| R | G | B | цвет | R | G | B | цвет | |
| 0 | 0 | 0 | черный | 1 | 0 | 0 | красный | |
| 0 | 0 | 1 | синий | 1 | 0 | 1 | розовый | |
| 0 | 1 | 0 | зеленый | 1 | 1 | 0 | коричневый | |
| 0 | 1 | 1 | голубой | 1 | 1 | 1 | белый |
Весь массив элементарных единиц изображения называют растром (лат. rastrum – грабли). Степень четкости изображения зависит от количества строк на весь экран и количества точек в строке, которые представляют разрешающую способность экрана или просто разрешение. Чем больше строк и точек, тем четче и лучше изображение. Достаточно хорошим считается разрешение 640x480, то есть 640 точек на строку и 480 строчек на экран.
Строки, из которых состоит изображение, можно просматривать сверху вниз друг за другом, как бы составив из них одну сплошную линию. После полного просмотра первой строки просматривается вторая, за ней третья, потом четвертая и т. д. до последней строки экрана. Так как каждая из строк представляет собой последовательность пикселов, то все изображение, вытянутое в линию, также можно считать линейной последовательностью элементарных точек. В рассматриваемом случае эта последовательность состоит из 640x480=307200 пикселов. Вначале рассмотрим принципы кодирования монохромного изображения, то есть изображения, состоящего из любых двух контрастных цветов – черного и белого, зеленого и белого, коричневого и белого и т. д. Для простоты обсуждения будем считать, что один из цветов – черный, а второй – белый. Тогда каждый пиксел изображения может иметь либо черный, либо белый цвет. Поставив в соответствие черному цвету двоичный код “0”, а белому – код “1” (либо наоборот), мы сможем закодировать в одном бите состояние одного пикселя монохромного изображения. А так как байт состоит из 8 бит, то на строчку, состоящую из 640 точек, потребуется 80 байтов памяти, а на все изображение – 38 400 байтов.
Однако полученное таким образом изображение будет чрезмерно контрастным. Реальное черно-белое изображение состоит не только из белого и черного цветов. В него входят множество различных промежуточных оттенков – серый, светло-серый, темно-серый и т. д. Если кроме белого и черного цветов использовать только две дополнительные градации, скажем светло-серый и темно-серый, то для того чтобы закодировать цветовое состояние одного пикселя, потребуется уже два бита. При этом кодировка может быть, например, такой: черный цвет – 002, темно-серый – 012, светло-серый – 102, белый – 112.
Общепринятым на сегодняшний день, дающим достаточно реалистичные монохромные изображения, считается кодирование состояния одного пикселя с помощью одного байта, которое позволяет передавать 256 различных оттенков серого цвета от полностью белого до полностью черного. В этом случае для передачи всего растра из 640x480 пикселов потребуется уже не 38 400, а все 307 200 байтов.
При записи изображения в память компьютера кроме цвета отдельных точек необходимо фиксировать много дополнительной информации – размеры рисунка, яркость точек и т. д. Конкретный способ кодирования всей требуемой при записи изображения информации образует графический формат. Форматы кодирования графической информации, основанные на передаче цвета каждого отдельного пикселя, из которого состоит изображение, относят к группе растровых или BitMap форматов (bit map – битовая карта). Растровое изображение представляет собой совокупность точек (пикселей) разных цветов. Наиболее известными растровыми форматами являются BMP, GIF и JPEG форматы.
Векторное изображение представляет собой совокупность графических примитивов (точка, отрезок, эллипс…). Каждый примитив описывается математическими формулами. Кодирование зависти от прикладной среды.
Растровая же графика обладает существенным недостатком – изображение, закодированное в одном из растровых форматов, очень плохо “переносит” увеличение или уменьшение его размеров – масштабирование. Для решения задач, в которых приходится часто выполнять эту операцию, были разработаны методы так называемой векторной графики. В векторной графике, в отличие от основанной на точке – пикселе – растровой графики, базовым объектом является линия. При этом изображение формируется из описываемых математическим, векторным способом отдельных отрезков прямых или кривых линий, а также геометрических фигур – прямоугольников, окружностей и т. д., которые могут быть из них получены. Фирма Adobe разработала специальный язык PostScript (от poster script – сценарий плакатов, объявлений, афиш), служащий для описания изображений на базе указанных методов. Этот язык является основой для нескольких векторных графических форматов. В частности, можно указать форматы PS (PostScript) и EPS, которые используются для описания как векторных, так и растровых изображений, а также разнообразных текстовых шрифтов. Изображения и тексты, записанные в этих форматах, большинством популярных программ не воспринимаются, они могут просматриваться и печататься только с помощью специализированных аппаратных и программных средств. Итак, любое графическое изображение на экране можно закодировать c помощью чисел, сообщив, сколько в каждом пикселе долей красного, сколько - зеленого, а сколько - синего цветов.